
Hem Chandra Joshi (Passionate Researcher)
👋 Hi, welcome!
This page presents our preprocessing-based methods for bias mitigation and fairness enhancement in machine learning models. These methods operate directly on training data before model training to reduce bias at its source. Since machine learning models learn patterns from data, biased training data can lead to unfair or discriminatory predictions. By addressing bias beforehand, preprocessing methods help produce fairer and more responsible and unbiased outcomes / decisions.
-
 IEEE Intelligent Systems
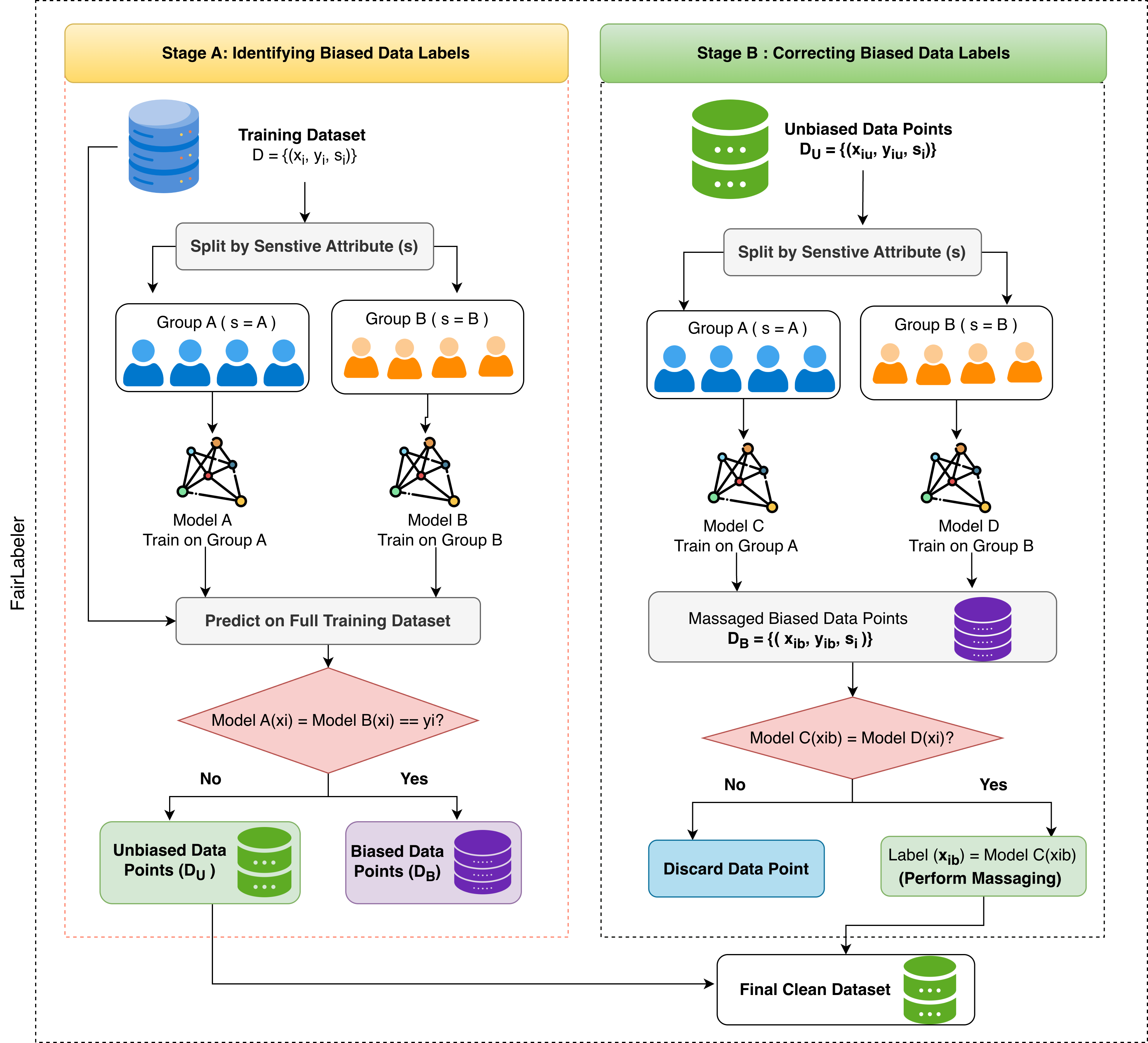
IEEE Intelligent SystemsFairLabeler addresses biased labels, one of the primary causes of bias in training datasets.
IEEE Intelligent Systems
IEEE Intelligent SystemsFairLabeler addresses biased labels, one of the primary causes of bias in training datasets. -
 IEEE Intelligent Systems
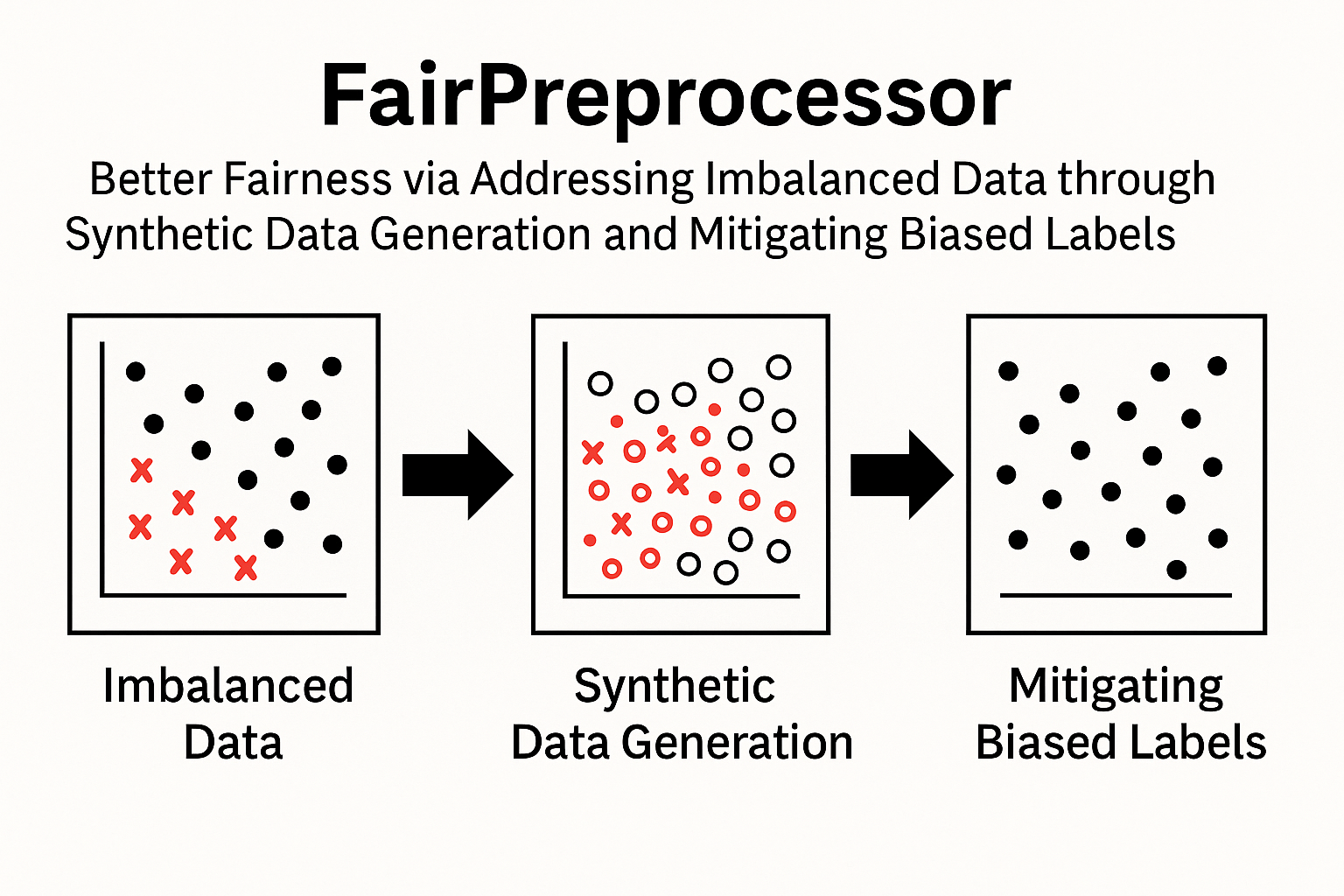
IEEE Intelligent SystemsFairPreprocessor addresses imbalanced data through rebalancing the internal data distribution using synthetic data generation based on differential evolution. It also identifies and removes biased labels through situation testing to develop fairer ML software.
IEEE Intelligent Systems
IEEE Intelligent SystemsFairPreprocessor addresses imbalanced data through rebalancing the internal data distribution using synthetic data generation based on differential evolution. It also identifies and removes biased labels through situation testing to develop fairer ML software. -
 ACM TOSEM
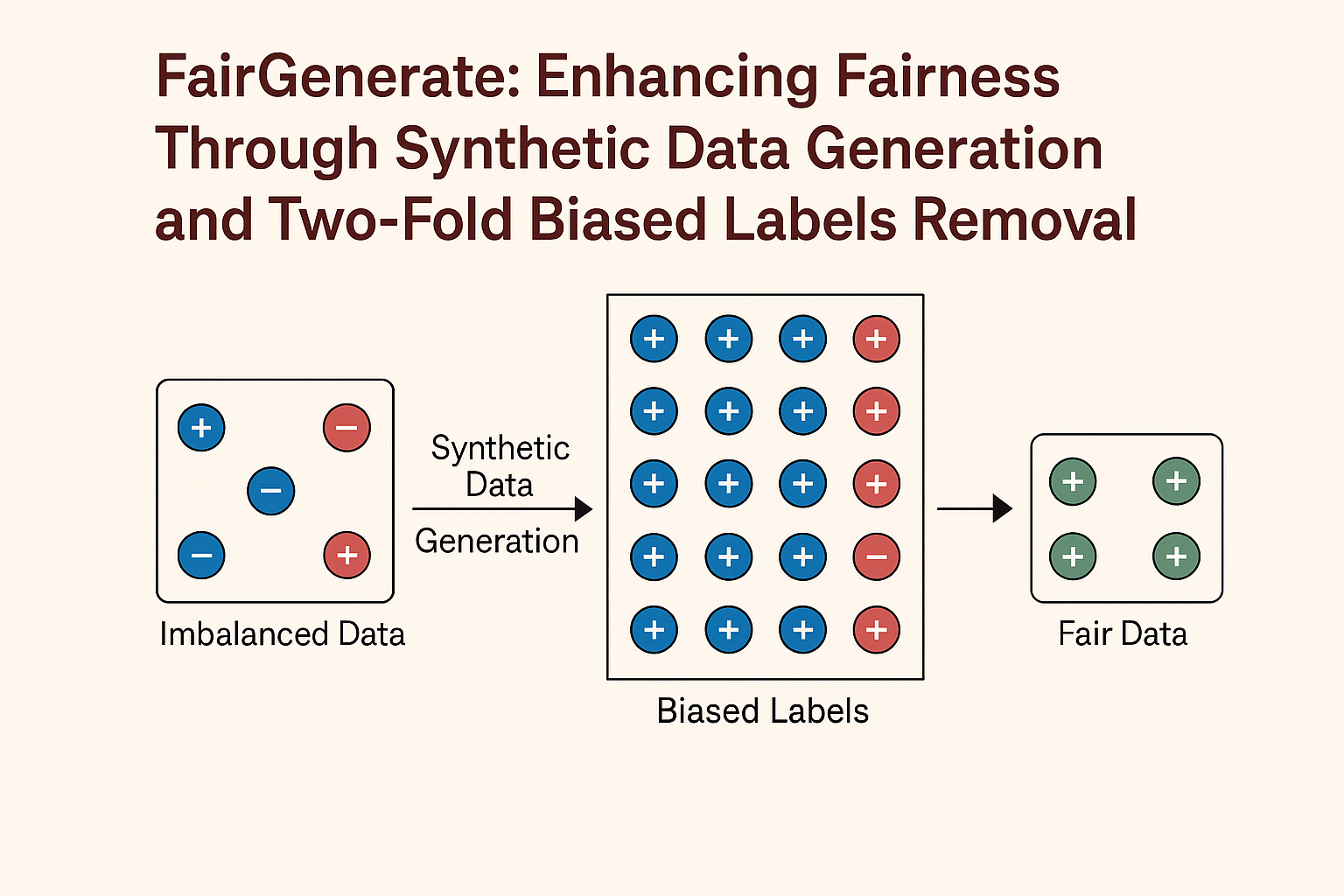
ACM Transactions on Software Engineering and MethodologyFairGenerate balances the internal distribution of training datasets based on class labels and sensitive attributes through synthetic data generation using differential evolution. It also identifies and removes biased labels before and after synthetic data generation to support the development of fair ML software.
ACM TOSEM
ACM Transactions on Software Engineering and MethodologyFairGenerate balances the internal distribution of training datasets based on class labels and sensitive attributes through synthetic data generation using differential evolution. It also identifies and removes biased labels before and after synthetic data generation to support the development of fair ML software.