
Hem Chandra Joshi
👋 Hi, welcome!
This page presents our preprocessing-based methods for bias mitigation and fairness enhancement in machine learning models. Preprocessing methods operate directly on the training data before any machine learning (ML) model is built. These approaches aim to reduce or eliminate bias at its source, as ML models learn statistical patterns from the data they are trained on. If the training data is biased, it can result in unfair or discriminatory predictions. By addressing bias prior to model training, preprocessing methods help ensure that downstream models produce fairer and more responsible outcomes.
-
 ACM TOSEM
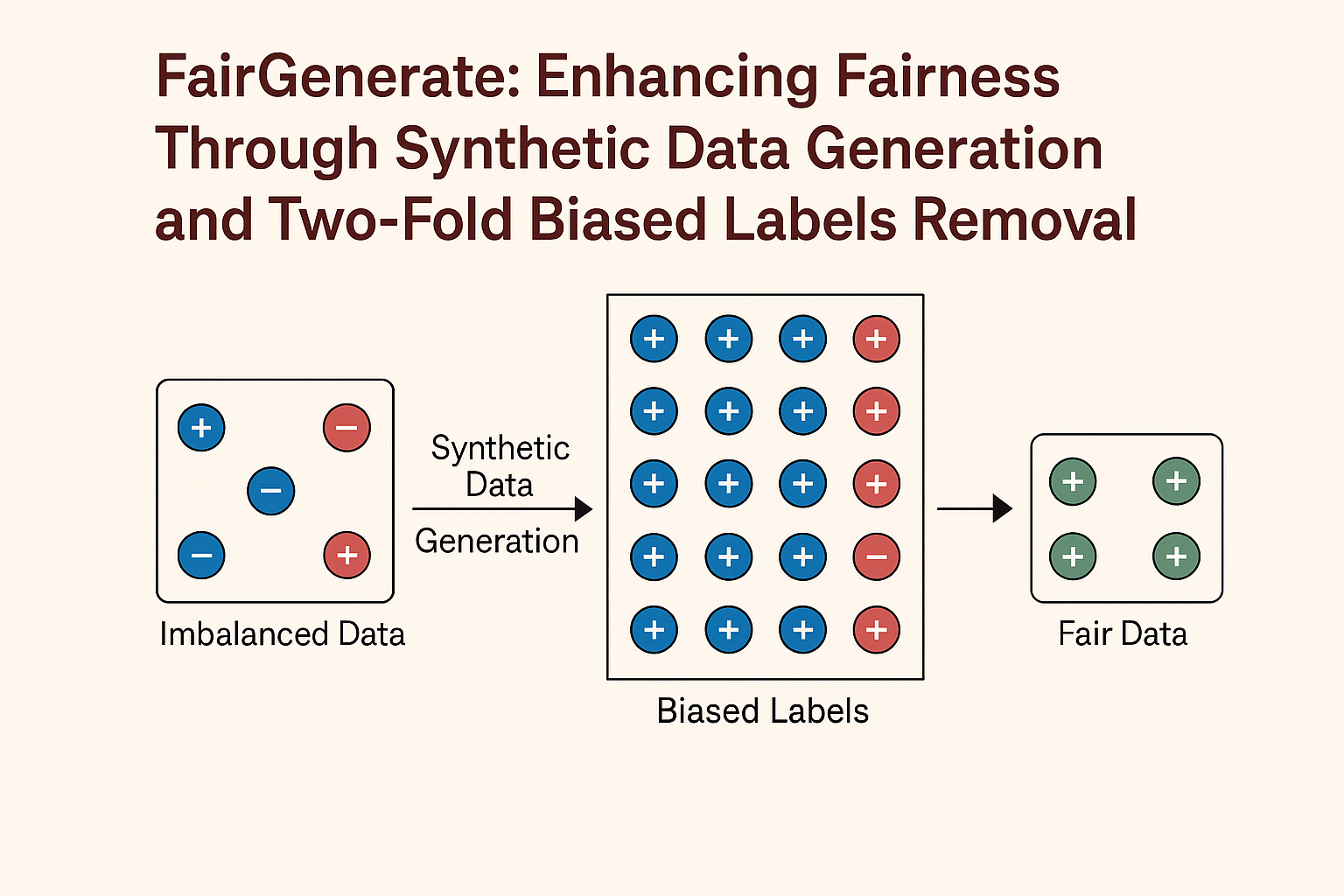
ACM Transactions on Software Engineering and MethodologyFairGenerate, a pre-processing method that (a) balances the internal distribution of training datasets based on class labels and sensitive attributes by generating synthetic data samples using differential evolution and (b) identifies the biased labels through situation testing and removes them before and after synthetic data generation, hence the development of fair ML software.
ACM TOSEM
ACM Transactions on Software Engineering and MethodologyFairGenerate, a pre-processing method that (a) balances the internal distribution of training datasets based on class labels and sensitive attributes by generating synthetic data samples using differential evolution and (b) identifies the biased labels through situation testing and removes them before and after synthetic data generation, hence the development of fair ML software. -
 IEEE Intelligent Systems
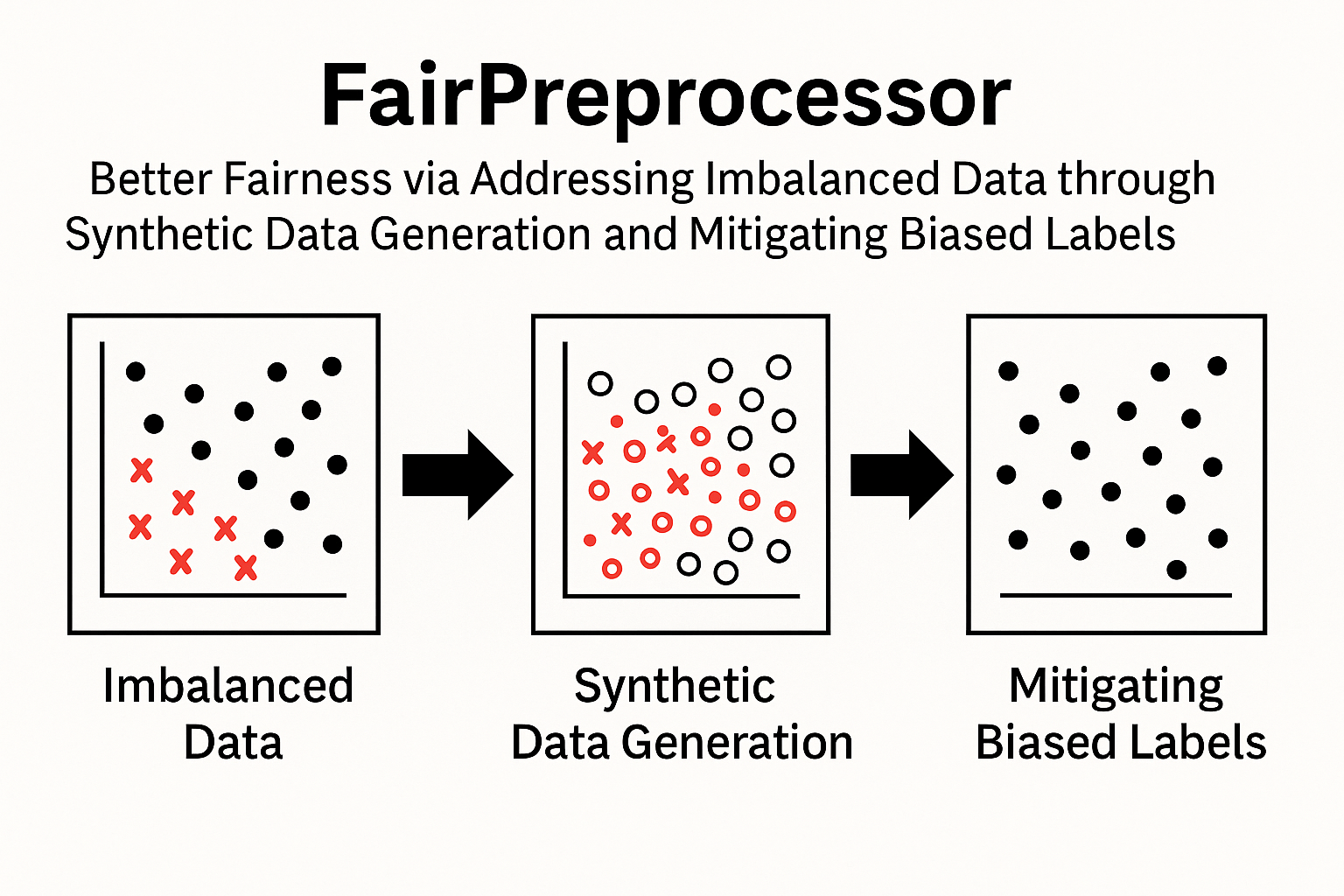
IEEE Intelligent SystemsFairPreprocessor addresses ’imbalanced data’ through rebalancing the internal data distribution by employing synthetic data techniques grounded in differential evolution. It also selects the most suitable crossover rate in synthetic data generation to achieve better fairness. Additionally, it identifies and removes biased labels through situation testing, thereby mitigating their effects and developing fairer ML software.
IEEE Intelligent Systems
IEEE Intelligent SystemsFairPreprocessor addresses ’imbalanced data’ through rebalancing the internal data distribution by employing synthetic data techniques grounded in differential evolution. It also selects the most suitable crossover rate in synthetic data generation to achieve better fairness. Additionally, it identifies and removes biased labels through situation testing, thereby mitigating their effects and developing fairer ML software.